乘风破浪的GPU
导演:欢迎今天的嘉宾,请自我介绍一下,姓名,年龄,职业还有出道时间!
GPU:还要介绍我是谁???那我这几十年白干了,都不知道我是谁。

我今天来就是来站C位的。
回想出道这几十年,一路风风雨雨,一路披荆斩棘,终于把手机、平板、台机、工作站、汽车、服务器、数据中心、超算、AI全部征服了。

导演:有实力,才有资格拽。你爸知道你这么拽吗?
GPU:知道啊,你看,他不就在那秀肌肉吗!

导演:我怎么听说有不少人对你是又爱又恨?
GPU:那是自然,人红是非多,想当年有人对我爱理不理,今天就让你高攀不起。
乘风破浪的GPU
AI运算由云端训练开始,其后是以CPU+GPU+云计算为核心的云端推理过程,最后导向设备端推理。大规模GPU的应用对AI产生了显著的加速效果。通过最新的数据中心级别GPU将AI的云端训练时间从数周直接降至以小时计算,为云端推理过程带来了巨大的加速度。
作为深度学习上游训练端的大杀器,数据中心GPU为N厂带来丰厚商业回报。与之相对比的是,搭载GPU的服务器售价超级昂贵。一时间,AI开发者“苦GPU久矣”。
举个栗子,假设一个企业有500个AI算法工程师,日常需要处理算法开发,算法验证、收集数据,训练模型,调参等多种并发任务。如果给每个工程师每人分配一张GPU卡,那成本得有多高。
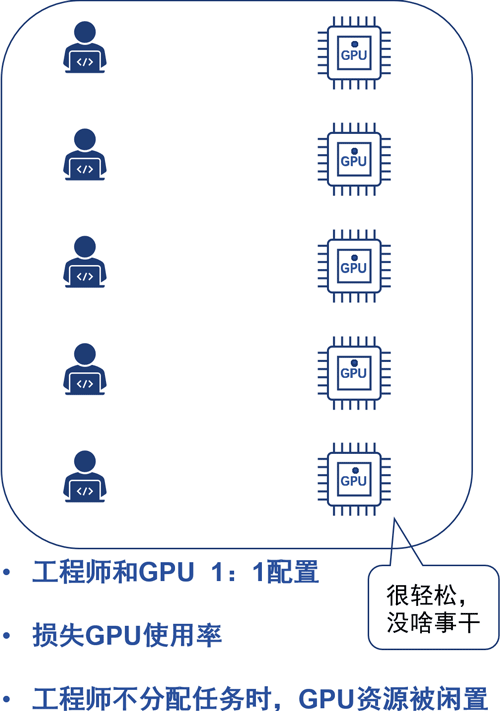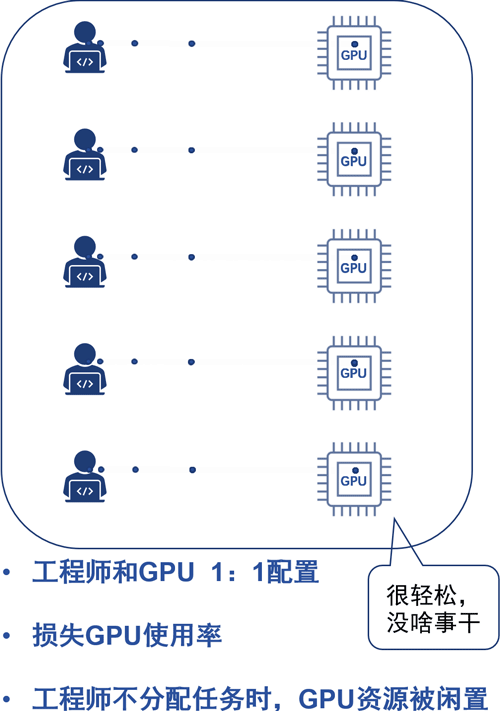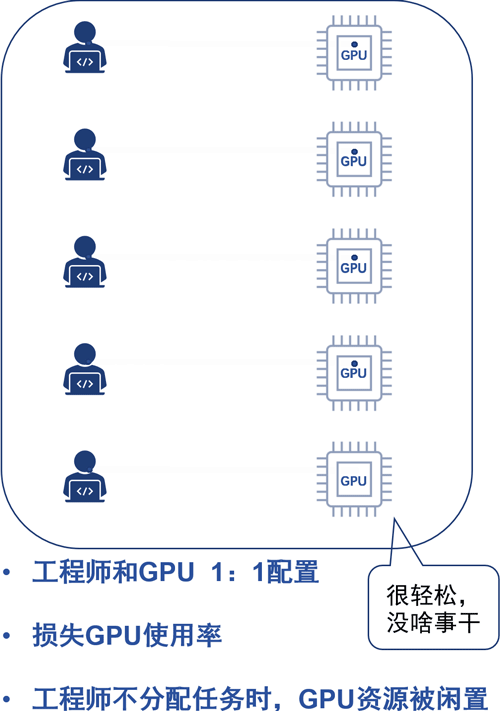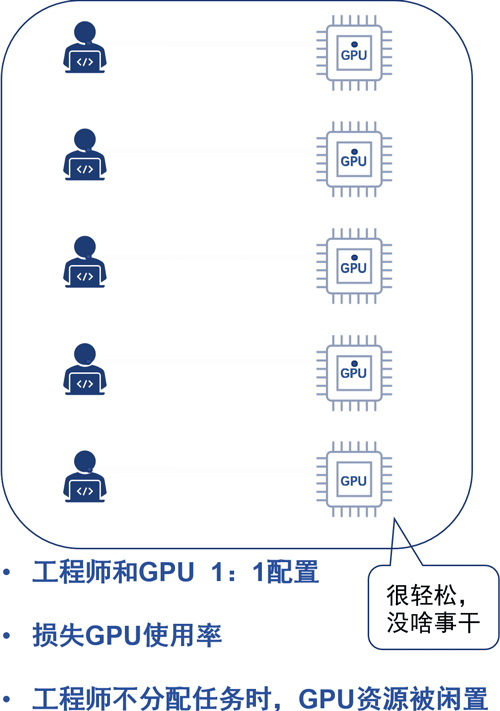
在现实中,大量GPU资源闲置,综合利用率不到20%的情况并不罕见。好钢用在刀背上。
假设按5个算法工程师配1张GPU卡,排队使用呢?
嗯,是可以节约大量GPU的成本,但是浪费了宝贵的工程师时间。
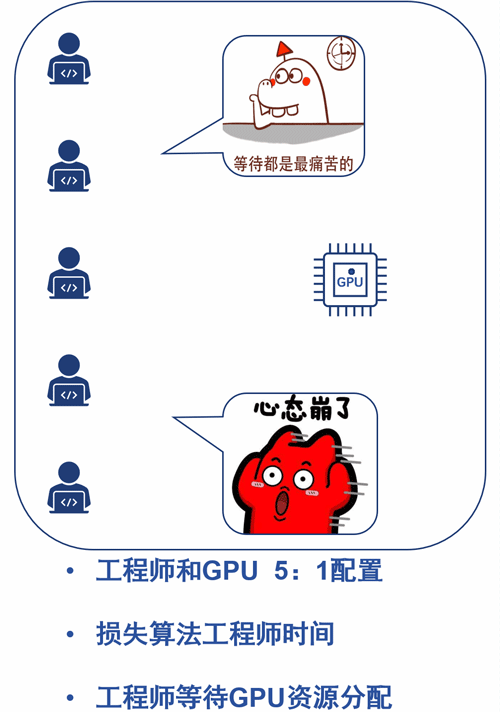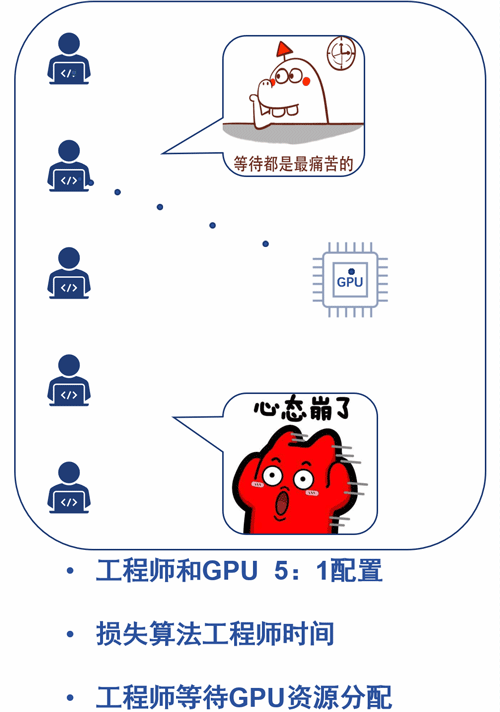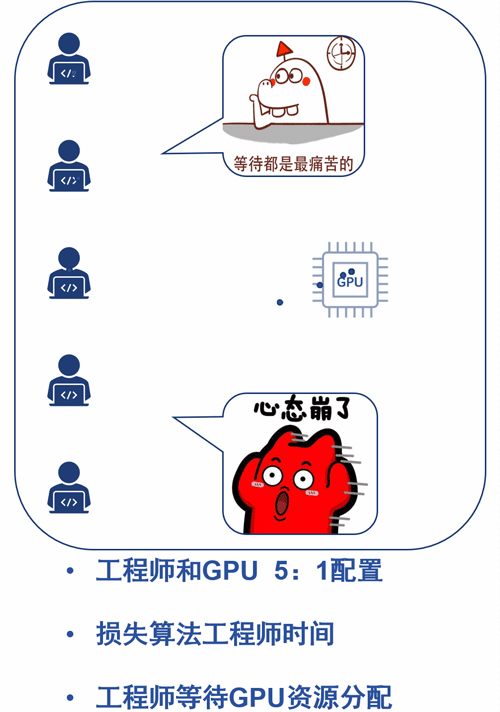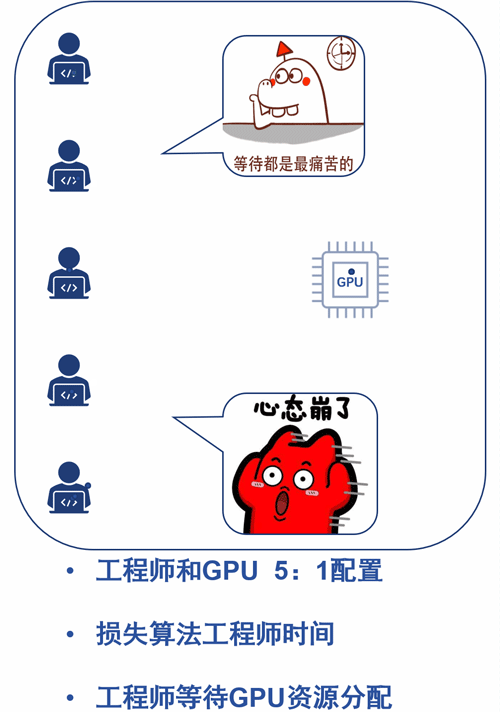
辣么高offer请来的算法工程师,你忍心这样对待?
GPU资源这么昂贵,怎么分配都不能让各方满意,难怪让人爱恨交加。
为了解决上述问题,一个更合理的思路是,将上述100张GPU卡汇聚成资源池来实现资源共享,借助软件定义,动态分配,弹性伸缩,就能很好的解决了上述问题。
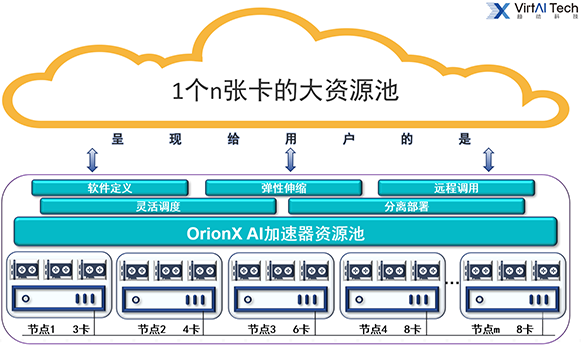
通过趋动科技OrionX软件,将企业内所有GPU节点打通,构成一个统一资源池,为任意AI部门、任意多个项目组提供共享资源,这将让每位算法工程师可以自由地获取资源。
模型的差异,算法的不同,网络的层数,对GPU资源的调配也不尽相同。如果每个算法工程师还要去了解底层硬件复杂的配置情况,GPU配比,这对于他们而言太难了。
要让算法工程师去做自己擅长的事,资源调配的工作交给OrionX。
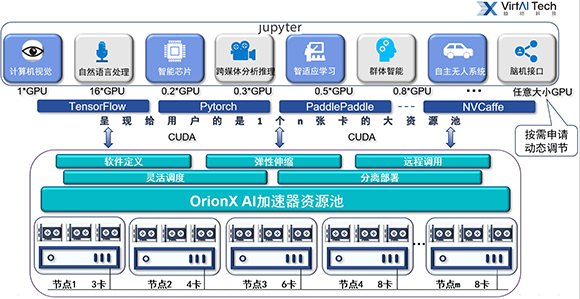
在这个OrionX构建的GPU资源池里面,任何算法工程师只需知道底下有n张GPU卡可供调用,无需关心GPU卡在哪,无需改任何代码,任意部署,快速上线,弹性伸缩,透明使用。
从此,GPU资源的分配变成一件很愉快的事情,每个算法工程师可以随时随地使用任意大小GPU;100张卡起到了500张卡的效果;算法工程师们可以专注于更有价值的上层应用开发;皆大欢喜。
曾经在工作中乘风破浪、历尽千帆。有了OrionX,你会变得一帆风顺。


